딥러닝으로 인해 컴퓨터 비전은 크게 발전하고 있습니다. 컴퓨터 비전의 핵심 과제 중 하나는 단일 이미지에서 여러 객체를 식별할 수 있는 정확한 ML모델을 작성하는 것이라 할 수 있습니다. 2017년 6월 Google에서는 이러한 컴퓨터 비전을 위한 최첨단 머신러닝 시스템으로 TensorFlow Object Detection API를 배포하였습니다. 이번 포스팅에서는 Object Detection API의 간단한 소개와 사용법에 대해 설명드리겠습니다.
소개
구글이 배포한 Object Detection API은 COCO detection challenge에 중점을 둔 TensorFlow 위에 구축 된 오픈 소스 프레임 워크입니다. 이 시스템의 목표는 최첨단 모델을 지원하면서 보다 빠른 연구를 가능하게 하는 것입니다.
- 다음과 같은 훈련가능한 Detection 모델을 선택할 수 있습니다.
- Single Shot Moultibox Detector (SSD) with MobileNets
- SSD with Inception V2
- Region-Based Fully Convolutional Networks (R-FCN) with Resnet 101
- Faster RCNN with Resnet 101
- Faster RCNN with Inception Resnet v2
- COCO dataset으로 학습된 고정 가중치가 각 모델들의 out-of-the-box 추측 목적으로 사용됩니다.
- 구글 클라우드와 로컬에서 모두 학습과 평가가 가능합니다.
- MobileNet을 사용하는 SSD 모델은 가볍기 때문에 모바일 장치에서 실시간으로 실행이 가능합니다.
사용하기
1. 설치
tensorflow/models 레퍼지토리 clone 하기
git clone https://github.com/tensorflow/models.git
텐서 플로우 설치
# For CPU
pip install tensorFlow
# For GPU
pip install tesorflow-gpu
나머지 라이브러리 설치
# For ubuntu
sudo apt-get install protobuf-compiler python-pil python-lxml python-tk
sudo pip install Cython
sudo pip isntall Jupyter
sudo pip install matplotlib
# Using pip
sudo pip install Cython
sudo pip install pillow
sudo pip install lxml
sudo pip install jupyter
sudo pip install matplotlib
Protobuf 컴파일
Model과 Training Parameter를 구성하기 위해서 Protobufs를 사용합니다.
# 실행위치 : models/research/
protoc object_detection/protos/* .proto --python_out =.
PYTHONPATH에 라이브러리 추가
로컬에서 실행될 때는 tensorflow/models/research/slim 디렉토리가 PYTHONPATH에 추가되어야 합니다.
# 실행위치 : models/research/
export PYTHONPATH=$PYTHONPATH: `pwd`:`pwd`/slim
이 명령은 새 터미널을 시작할 때 마다 입력해주어야 하며, 이를 원치 않을 경우 ~/.bashrc 파일 마지막 줄에 이 명령을 추가하면 됩니다.
테스트
# 실행위치 : models/research/
python object_detection/builders/model_builder_test.py

같은 화면이 뜬다면 설치가 제대로 된 것입니다.
2. 실행
models/research/object_detection/object_detection_tutorial.ipynb를 Jupyter notebook을 사용하여 실행해볼 수 있습니다. 또한 models/research/object_detection/test_images에 원하는 이미지를 넣어서 해당 이미지에 대한 Detection을 실행할 수 있습니다.
- 모델 수정

- Pretrained model 다운받기
미리 학습된 모델을 다운받아 디텍션에 사용할 수 있습니다. 다운받은 파일에는 freeze된 모델과 체크포인트, 파이프라인이 있습니다. 위의 코드 부분에 MODEL_NAME, PATH_TO_CKPT, PATH_TO_LABELS, NUM_CLASSES를 수정해 주어야 하며 라벨의 경우 models/research/object_detection/data에 있습니다. 또한 tutorialdㅣ 실행된 위치는 models/research/object_detection이므로 모델을 수정할 때 PATH도 알맞게 수정해주셔야 합니다. - PATH_TO_TEST_IMAGES_DIR를 수정하여 원하는 폴더에 이미지를 넣어서 Detectiond르 실행할 수 있으며 IMAGE_SIZE를 수정하여 출력되는 이미지의 크기도 조절이 가능합니다.
- Jupyter 상에서 이미지를 출력해주는 plt.imshow()코드 대신에 scipy.misc.imsave()를 사용하면 Detection된 이미지를 로컬에 저장할 수 있습니다.
Detection 출력 화면
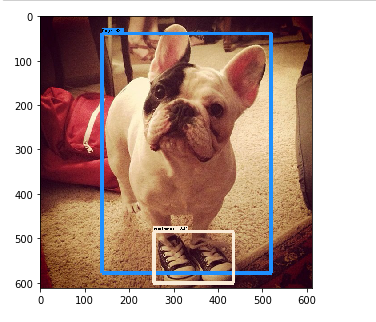
이번 포스팅에서는 Google Object Detection API의 소개와 사용법에 대해 알아보았습니다.
이상으로 포스팅을 마치며 다음 포스팅에서는 Object Detection API를 이용하여 모델을 학습하는 방법에 대해 설명 드리도록 하겠습니다.