MIT - Introduction to Computer Science and Programming in Python
Decision Tree
weight = [5,3,2]
value =[9,7,8]
max 5
e.g.1) decision tree
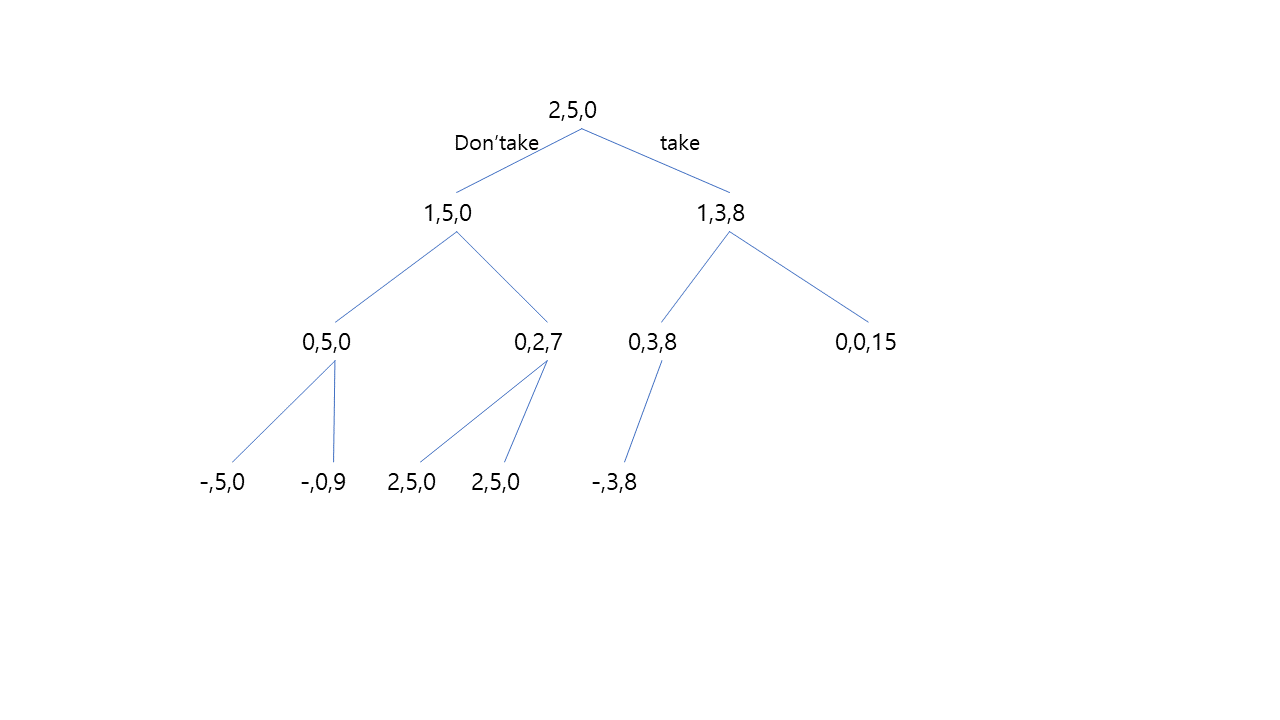
의사결정나무를 그리는 방법
의사결정나무를 그릴 때, 위에서부터 그리길 시작해야한다.
아이템의 인덱스값으로 아이템0,1,2라고 각각의 아이템을 지칭하겠다.
먼저, 아이템2을 백팩에 담거나 담지않는다는 결정을 해야한다.
만약 아이템2를 담지 않는다면 가방은 여전히 비어있게 된다.
그 다음, 아이템1을 고려한다. 아이템1을 담을 때, 담지않을 때를 나누어 고려한다.
아이템1을 담을 때, 가방의 무게는 3파운드로 2파운드를 더 담을 수 있고, value의 값은 7이 된다.
아이템1을 담지 않을 때, 가방의 무게는 그대로 5파운드를 더 담을 수 있고, value의 값은 0이다.
마지막으로, 아이템0을 담을 지 안 담을 지 고려한다.
그렇게 하나의 문제에 대해 2개의 브렌치가 생성되고, 가방이 담을 수 있는 무게인 5파운드를 넘기게 되면 브랜치가 생성되지 않는다.
교수님의 메세지
- 이진 의사결정나무(binary decision tree)에서 가장 하단의 노드들을 제외한 각각의 노드들의 해결방법은 그 노드에서 두 개의 브랜치를 뻗어 생성된 두 개의 노드들로부터 나온다.
yes or no가 아닌 다른 문제에선 어떻게 될까요?
이 때, 저번에 얘기한 최적 하부구조에 대해서 말할 수 있다.
저번시간에 최적화된 하부구조를 어떤 문제를 그보다 작은 하부 문제들로 최적 해결방법을 찾음으로써 해결할 수 있음을 의미한다고 말했다.
어려운 문제를 풀기 위해, 문제를 작은 문제들로 나누어 그것들의 해결방법들을 합친다. 이번 경우에는, 해결방법을 합치는 것이 아니라 a와 b 중 최고의 것을 고르는 것이 곧 합치는 것이라고 라할 수 있다.
그 예가 저번시간에 한 maxVal이다.
e.g.2) using with optimal substructure
>>> def maxVal(w,v,i,aW):
... global numCalls
... numCalls +=1
... if i ==0:
... if w[i] <= aW:
... return v[i]
... without_i = maxVal(w,v,i-1, aW)
... if w[i] > aW:
... return without_i
... else:
... with_i = v[i] + maxVal(w,v,i-1, aW-w[i])
... return max(with_i, without_i)
큰 문제에서 실행되는 이 함수가 오래걸리는 이유는 같은 행동을 계속해서 같이 일을 하고 있기 때문이다. 같은 행동을 계속하는 이유는 큰 문제의 많은 양의 하부문제들이 같기 때문이다.
Memoization
이러한 의사결정 나무는 memoization을 생각하게 만든다. 메모는 다이나믹 프로그래밍의 핵심 아이디어라고 할 수 있다. 다이나믹 프로그래밍은 매우 유용하다. 인풋값이 아무리 큰 벡터라도 다이나믹 프로그래밍을 통해 연산량을 줄여서 효율적으로 계산할 수 있다.
order(n,s) , s space
n : 아이템 개수
s : 배낭 사이즈
모든 아이템을 자유롭게 담을 수 없어서 s space를 제약으로 둔다.
내가 이용하려고 한 사이즈는 배낭에 담을 수 있는 아이템의 개수이다. 왜냐하면 이것의 실제 실행 시간과 이 알고리즘의 실제 공간이 지배적이기 때문에, 흥미롭게도 문제의 사이즈로부터가 아닌 해법의 사이즈(size of solution)로부터 충분하다.
size of solution
얼마나 많이 실행해야하는 것은 얼마나 많은 아이템을 배낭에 담을 수 있는 가와 연관되어있다. 내가 기억해야만 하는 아이템의 개수는 배낭안에 얼마나 많이 담을 수 있는 지와 연관되어 있다. 그리고 실행시간의 양은 정확하게 내가 기억해야하는 물건들의 개수이다.
이것은 우리가 즐겨 말하는 복잡도의 방식이 아니다.
우리가 order에 대해 말하면, 항상 이 문제의 사이즈에 대한 term에 대해서 말했다. 왜냐하면 일반적으로 우리가 해결하기 까지 우리는 그 해법의 사이즈를 몰랐기 때문이다.
그래서 우리는 인풋의 관점에서 order를 오히려 정의해보아야한다.
pseudo-polynomial algorithm
polynomial(다항식) 알고리즘은 입력값의 사이즈에 따른 다항식이다.
만약 numerical algorithm(수치 알고리즘)을 생각해본다면, pseudo-polynomial algorithm은 인풋의 수치값을 다항식으로 나타낸 running time을 갖는다.
이것의 핵심 이슈는 수치값이다.
수치값
우리가 그 값이 자릿수로 기하급수적임을 안다.
기억했으면 좋겠는 것
- 다이나믹 프로그래밍에서 우리는 공간을 위해 시간을 거래하고 있다는 점.
- 지수 문제들로부터 주눅들지마라
사람들은 이 문제가 지수문제로 풀지 못한다고 말하는 경향이 있다. 분명하게 지수할 수 있을 지라도, 사실상 그 문제를 더더욱 빠르게 풀 수 있을 것이다. - 다이나믹 프로그래밍은 광범위하게 유용하다.
만약 최적 하부구조를 가지고 있고, 하부 문제들을 중첩하고 있다면 다이나믹 타이핑을 사용할 수 있다. 그래서 그것은 배낭문제를 풀기 좋고, 변화를 만들어가는 것에도 좋고, 또 전체 변화에도 적용하기 좋다. - 문제 감소의 전체적 개념 기억하기
언제나 너는 무언가를 이전에 해결한 적이 있는 문제로 감소시킬 수 있다. 그것은 좋은 것이다. 사람들은 첫 번째 질문을 두고 자기 자신에게 이 문제를 예전에 풀어본 적이 없나, 해결했었던 문제의 개념과 같지만 다른 문제가 아닐까라는 생각을 하는 경향이 없다.
Module(modularity)
모듈 = 연관된 기능들의 모음
모듈은 프로그램들을 Divide and conquer(나누고 합치는 것)이다. 그래서 우리는 짧은 시간에 쉽게 모듈을 사용해 문제를 해결할 수 있다.
e.g.3) module
import math
math.sqrt(11)
점 표기법
충돌되는 이름을 피하기 위해 점 표기법은 중요하다.
e.g.4) dot notation
import set
import table
table.member(e,t)
class
모듈안에 클래스 를 포함한다.
객체지향프로그래밍 상에서 클래스를 이용하는 것을 강조할 것이고,객체지향프로그래밍을 사용할 것이다.
전형적으로 데이터 추상화 라고 일컫는 무언가를 만들기 위해서 사용한다. 데이터 추상화의 동의어는 추상 데이터 유형이다.
객체지향 프로그래밍
객체는 데이터와 함수의 모음이다.
여기서 핵심은 데이터와 함수를 같이 묶어 데이터를 하나의 것으로 간주하여 작동시키는 것이다.
이것의 이점은 객체를 또다른 프로그램으로 패스할 때, 그 프로그램 또한 객체에 여러가지 연산을 적용할 능력을 갖는다. 그 전 프로그램에서 이 객체가 어떠한 타입을 갖고 있는 지는 크게 중요하지 않다.
데이터에 대해서 데이터와 함수들을 결합시키는 것은 객체지향 프로그래밍에서 매우 본질적인 것이다. 그리고 캡슐화 라는 것도 자주 사용된다.
알약같은 캡슐을 가졌다고 생각하자. 그 캡슐 안에는 데이터와 함수들로 이루어진 방법론들이 있다.
객체지향의 문맥상에서 캡슐화를 설명하였을떄, 전형적으로 메시지 전달의 관점에서 본다. (메세지 전달은 은유적 표현이다.)
Message passing mataphor
하나의 객체는 다른 객체에게 메시지를 전달할 수 있고, 메세지를 받은 객체는 그 메세지의 방법론을 객체에 실행함으로써 반응한다.
e.g.5) list - Message passig mataphor
list의 경우로 생각해보자
l.sort()
l : 객체 / sort : 메세지
메세지는 sort 방법론을 찾고 객체인 l에 적용하라고 말한다.
다시 정리하면, 클래스는 공통된 특징을 지닌 객체들의 모음이다.