논문 출처 : https://arxiv.org/pdf/1706.01427.pdf
오늘 리뷰할 논문은 딥마인드에서 2017년에 발표한 Relatinal Network 입니다. 모델의 architecture 를 살펴보기 전에 관계추론이 무엇인지에 대해 가볍게 살펴보겠습니다. 우리가 분류문제를 해결하고자 할 때와 달리 관계추론(Relational reasoning)은 상호 object들과의 관계를 살피고 답을 유추하는 것이 목적입니다.

위의 이미지는 관계추론의 모델에서 쓰이는 CLEVER 데이터셋의 일부입니다. 우리가 일반적인 분류문제나 Detection 을 풀고자 한다면 원통은 몇 개, 빨간 색 구의 여부, 등을 파악할 수 있을 것입니다. 하지만 이러한 경우 “파란색 정육면체 뒤에 있는 구는 어떠한 색을 가지고 있니?” 라는 질문은 해결 할 수 없습니다. 하지만 관계추론 모델의 경우 어떠한 환경(이미지) 에서 존재하는 객체들(ex, 구, 직육면체, 정육면체)과의 상호적인 관계를 따져 답을 유추하는 모델입니다. 그럼 이제부터 모델의 구조를 보면서 하나씩 살펴보겠습니다!
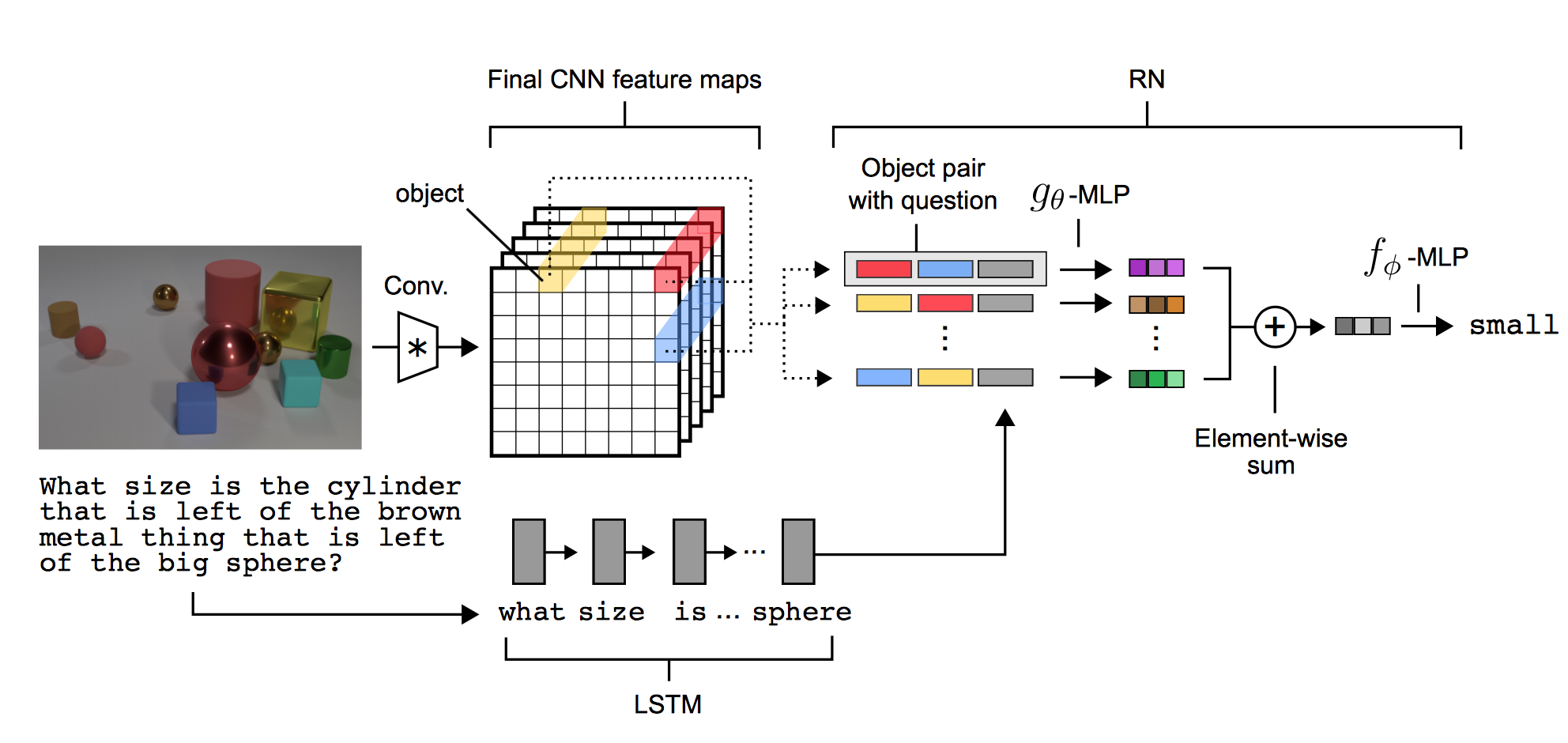
위의 구조가 논문에서 제시한 모델의 구조입니다. 이 구조는 크게 CNN, LSTM, RN 이며 RN 을 이용해서 object 들의 관계를 나타냅니다. RN 에 대한 설명은 잠시 뒤로 미루고 인풋레이어부터 살펴보죠!
visual QA 의 경우 input 으로 필요한 것은 무엇일까요? 모델의 구조에서 볼 수 있듯이 이미지와 이미지에서 물어보고 싶은 질문이 될 것입니다.
CNN
논문에 따르면 CNN 은 총 4개의 convolutional layer를 가지는데 각각의 convolutional layer 는
convolution + ReLu non-linearity + batch normalization 으로 이루어져 있습니다. Max-pooling 은 사용하지 않았는데 논문에서 언급하지는 않았지만 이유를 생각해보자면
이미지에서 존재하는 각각의 object 간의 positional relation 를 가지고 가야 하기 때문이고 Max-pooling 을 이용하게 되면 FOV(Field Of View)를 넓힐 수 는 있지만
그에따른 object 의 다양한 정보들의 손실이 불가피하기 때문에 pooling을 사용하지 않은 것 같습니다. 다시 모델의 구조를 보면 4번의 convolutional layer를 거치게 될 경우
의 크기를 가지는 개의 feature map 이 형성되어집니다.
그렇다면 이 feature map 에서 어떻게 object 를 선택할까요.
모델구조중 Final CNN feature maps 에서 볼 수 있듯이 하나의 sub-object 는 feature map 의 같은 위치의 값들의 벡터로 이루어 집니다. 위의 구조에서는 빨, 파, 노 로 이루어진 벡터들이겠죠?
각각의 object 들은 texture, conjunction of physical objects, background 등을 나타낼 수 있습니다. 이렇게 object 들을 선택하게 되면 각각의 object 들간의 상호 공간적인 관계는 표현하지 못하더라도
object 의 location 정보와 좀 더 다양한 object 의 특성들을 가지고 갈 수 있게 됩니다.
LSTM
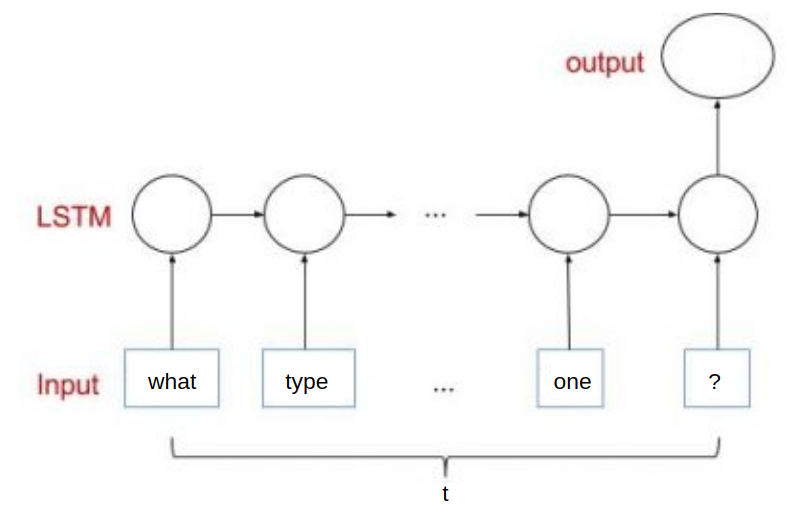
LSTM 의 경우 논문에서는 final state 만을 이용합니다. 여기서는 LSTM 에 대해서 설명하지는 않겠습니다. LSTM 의 인풋으로는 lookup table 의 trainable word vector 입니다. 그림에서 알 수 있듯이 time-step 마다 word 단위의 vector 가 input으로 이용이 되며 최종적인 state 의 output 값과 CNN 의 구조의 object vector 의 조합으로 RN 네트워크를 형성합니다.
RN
이제 이 논문의 핵심인 RN 에 대해서 알아보겠습니다. RN 의 구조는 굉장히 simple 하지만 좋은 성능을 보였습니다. 제가 생각하기에 RN을 간단히 나타내자면 object 조합에 대한 fully-connected 라고 생각합니다. CNN을 통해서 나온 object의 invariant properties 와 LSTM을 통해서 나온 질문에 대한 output 값을 사용해서 object 들간의 관계추론을 학습합니다. 그럼 RN 의 수식을 한 번 볼까요?
이 한줄이 RN 의 수식입니다. 이겠죠? 수식에 따르면 모든 조합을 따지지만 논문의 저자는 모든 조합을 이용하지 않아도 된다고 합니다. 따라서 어떠한 문제를 푸느냐에 따라 유동적으로 선택하면 될 듯 합니다. 는 MLP 이며 의경우 3 fc-layer로 이루어져 있으며 각각 256 의 unit 을 가지고 있습니다. 또한 3 fc-layer 이며 256, 256, 23 의 unit 개수를 가집니다. 의 마지막 layer를 제외한 layers는 ReLu 를 사용했습니다. 의 마지막 layer 는 classes 에대한 확률로 표현이 되게끔 softmax 를 사용합니다.
직관적인 이해를 위해 모델의 구조와 함께 살펴보겠습니다.
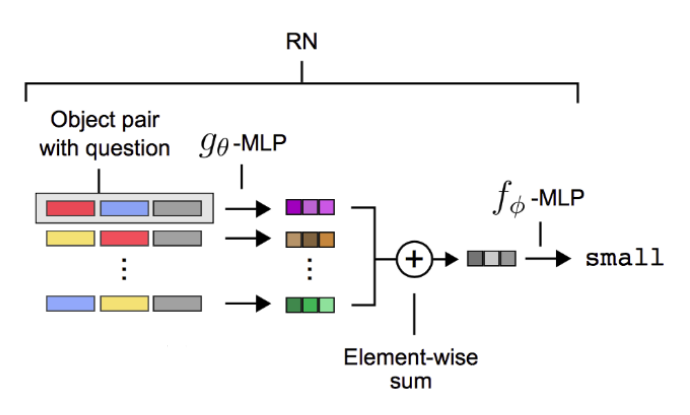
CNN 의 마지막 feature map에 대한 object 는 각각의 순서쌍으로 concatenate 되어 있습니다. 순서쌍으로만 끝나는 것이 아니라 각각의 순서쌍에 대해서 LSTM 의 final state output(q) 을 이어주게 됩니다. 으로 구성이 되어 지겠죠? 그 다음 각각의 조합에 대해서 를 적용시킨 후 element-wise sum을 하게 되면 object들의 관계에 대한 표현이 나태내어 집니다. 마지막으로 로 classification 을 거쳐 최종적인 output 을 뽑아냅니다.
논문에서는 loss function 으로 cross-entropy 를 사용하며 Adam optimizer 를 사용했습니다. RN 의 구조는 굉장히 간단하지만 성능면에서 SOTA(state-of-the-arts) 를 보였습니다. 여기까지가 모델에 대한 설명이고 다음 포스팅에서는 RN을 Tensorflow로 구현해 보는 시간을 가지겠습니다!