SIGIR(Special Interest Group on Information Retrieval) 2019
21 - 25 July, 2019, Paris, France

이번 달 21일부터 25일까지 5일간 프랑스 파리의 Cité des sciences et de l’industrie에서 SIGIR 2019가 열렸습니다. 첫 해외학회인지라 설레기도 하면서 한편으로는 장기간의 비행에 걱정도 되었습니다. 학회 참석 전에 연구실 내부적으로 학회에 제출된 논문들을 미리 읽어보고 발표하는 시간을 가졌습니다. 논문을 읽기만 할 때와 다르게 저자의 발표를 직접 듣고 질문할 수 있는 좋은 기회이기 때문에 많은 기대를 안고 학회에 참석했습니다.
또한 학회장에는 Facebook, Naver, Apple, Rakuten과 같은 여러 글로벌 기업들이 홍보 부스를 열고 recruiting을 하고 있었습니다. 각 부스를 돌며 recruiting 문서를 봤는데, 다른 기업들은 런던, 파리, 싱가폴 등에 사무실이 있어 현실적으로 지원이 어려웠지만(제 실력도..), Rakuten의 경우 도쿄에 회사가 있어 담당자님과 많은 대화를 나누고, 앞으로 어떤 준비를 해야 할지 알 수 있어 좋았습니다. 또한 여러 부스에서 에코백이나 티셔츠같은 기념품을 줘서 돌아올 때 짐이 상당히 무거워졌습니다.
Tutorial(Extracting, Mining and Predicting Users’ Interests from Social Networks)
첫 날은 오전, 오후 모두 Tututorial이 진행되었습니다. 저는 그 중에서도 소셜 네트워크 데이터에서 사용자의 흥미를 예측하고 추천해주는 방법에 대한 튜토리얼을 들었습니다. 튜토리얼은 소셜 네트워크 데이터 마이닝의 소개, User Interest 모델링 방법, 미래방향의 세 가지로 구성되어 있었습니다. 튜토리얼 자체는 전부 twitter 데이터를 이용한 모델링에 대해 설명했고, 주로 teewt의 텍스트와 위키백과 페이지와의 Linking을 위주로 되어 있어, 이 분야의 전체적인 모델과 개념에 대해서 설명한 것이 아니라, 지엽적인 부분에 대한 내용인 것 같아 약간은 아쉬웠습니다.
기억에 남는 모델링 방법으로는, twitter 공인 계정의 프로필을 이용하여 계정과 공식 홈페이지 및 wikipedia 페이지 링크하기, 어떠한 topic에 대해 hierarchical하게 세부 토픽으로 categorize하기, user-topic 그래프를 이용하여 컨텐츠 추천하기 등이 있었습니다. 대부분의 데이터가 interested - not interested의 binary로 되어 있어, 성능을 평가할 때에나 사용자에게 추천할 때 interested일 확률이나 sigmoid값의 내림차순 등으로 추천을 해줬습니다. 저는 단순히 interested, not-intersted로 나누는 것이 아니라 흥미의 정도를 나타낼 수 있는 numeric한 척도가 있다면 현실에서의 실제 interest를 더 잘 반영할 수 있을 것이고, 이 척도를 바로 비교하거나 연산할 수 있고 성능 측정도 더 정확하게 이루어질 수 있을 것이라는 생각이 들었습니다. 또한 텍스트를 wikipedia 페이지와 linking하는 것은, 여러 줄임말이나 slang이 사용되는 sns 데이터와 맞지 않고, 새로운 개념이나 신조어가 wikipedia에 즉각적으로 정리되지 않는다는 점에서 과연 소개한 모델이 현실에서 얼마나 활용도가 있을지 궁금해, 발표가 끝난 후 저자에게 질문했습니다. 답변으로 1) 흥미를 numeric하게 정하는 것은 결국 사람의 주관이 필요하다. 클릭을 했다 <-> 하지 않았다. 구매를 했다 <-> 하지 않았다. 등 객관적인 데이터를 사용하다보니 그렇게 되었다. 또, binary 데이터일지라도, 모델의 결과를 통해 충분히 계산 가능한 값이 나온다. 2) 영어 데이터도 물론 여러 줄임말이나 slang이 있다. 그리고 새로운 개념이 계속적으로 생기는 것도 맞다. 하지만, 데이터를 wikipedia 문서와 linking하는 것만으로도 충분히 가치있다. 라는 답변을 들었습니다. 제가 아직 실제 소셜 데이터를 이용한 실질적인 프로젝트에 참가해본 적이 없어, 랩실에서 공부하는 것과 현업에서 이루어지는 분석이 많이 다르다는 것을 느꼈습니다.
Warm Up Cold-start Advertisements: Improving CTR Predictions via Learning to Learn ID Embeddings
Click-through rate(CTR)을 예측하는 것은 광고 산업에서 가장 활발히 연구되는 분야 중 하나입니다. CTR을 예측하는 여러 모델이 있지만, 광고의 배너 크기가 작거나, 새로운 광고가 등록되는 경우, 이 데이터에 대해서 모델이 학습을 더디게 하는 cold-start 문제가 있다고 합니다. 이 저자는 이러한 문제를 광고 ID Embedding을 통해 해결하고자 했습니다.
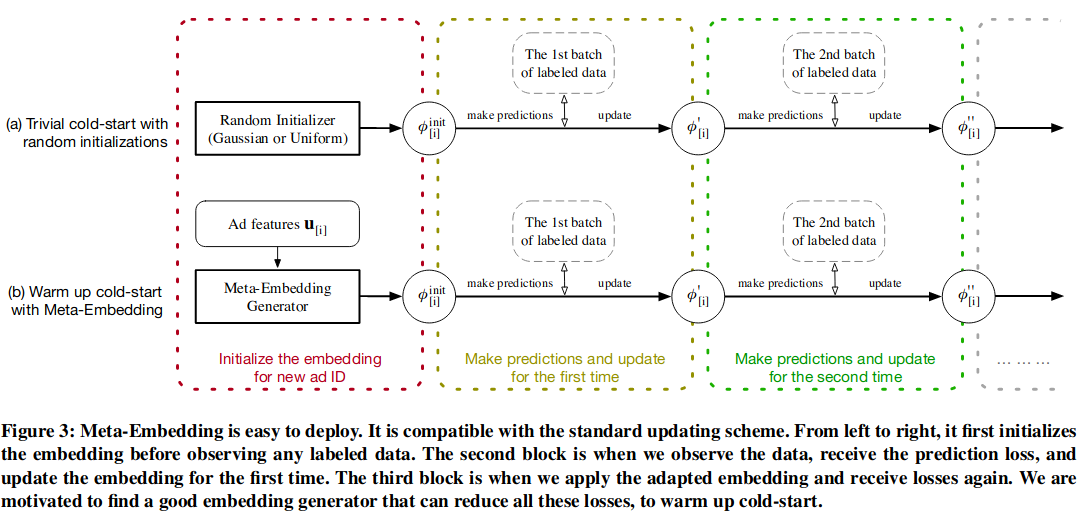
모델은 Cold-start phase와 Warm-up phase 두 가지로 나누어져 있고 loss 역시 두 가지입니다. 하나의 배치 단위에 두 가지 loss가 동시에 발생하는(동시에 학습하는), 구조로 되어 있습니다. 하나의 배치가 두 데이터 a와 b가 있을 때, a 데이터로 메타 임베딩 loss를 구하고, b 데이터로 validate하며 역시 loss를 구합니다. 그리고 두 loss를 $\alpha$ 파라미터를 이용하여 더한 후 학습합니다.

이를 통해 새로운 광고가 추가되어도, 새로 모델을 학습할 필요 없이 광고의 metadata만으로 예측이 가능하다는 것이 저자의 설명이었습니다. 이 발표에 대해 몇가지 질문이 있었는데,
Q) 결과를 보면, 당신 모델만 매우 뛰어나게 나타난다. 메타 임베딩 없이 실험했을 때는 어땠는가?
A) 해보진 않았는데, 아마 우리만큼 잘 나오진 않을 것이다.
Q) 파라미터 $\alpha$가 작은데(0.1), 왜 그렇게 정했는가?
A) 우선, warm-up에 집중하는 것이 더 중요하기에 $\alpha$를 작은 값으로 했다. 또, 0.3, 0.5, 0.7로 실험해봤는데, 파라미터별 성능차이가 거의 없었다.
저는 이 답변을 듣고, $\alpha$에 따라 성능 차이가 크지 않았다면 굳이 두 phase로 나누지 않고 metadata만을 이용하여 모델링 했어도 좋은 성능을 냈을 것 같다는 생각이 들었습니다. 그러나 한 배치 단위를 두 데이터셋으로 나누어 두 phase에 대한 loss를 계산했다는 점이 흥미로웠습니다.