KCC2018 정보과학회 후기
2018.06.20 ~ 2018.06.22까지 제주도에서 열린 KCC2018(한국컴퓨터종합학술대회)에 참석했습니다. 제가 공부를 시작하고 난 후 경험해본 두 번째 학회였는데, 비교적 좁은 분야의 발표가 많았던 지난 대한산업공학회와는 달리 정말 다양한 분야의 연구자들이 각자의 Domain에서 여러 알고리즘을 적용시킨 사례를 발표하였습니다. 안내받은 순서대로 발표가 진행되지 않아 듣고 싶었던 발표를 듣지 못한 경우도 몇 번 있었지만, 제가 들은 발표 중 기억아 남았던 두 가지 발표를 여러분께 소개하고자 합니다.
대량의 데이터와 인공신경망을 이용한 뇌-컴퓨터 인터페이스의 학습단계 최소화
뇌-컴퓨터 인터페이스(Brain-Cumputer Interface, BCI)란, 뇌파를 이용하여 특정 기기를 제어하는 기술을 의미합니다. 이 논문에서는 6X6 행렬의 자판에 입력된 글자가 무작위로 깜빡이면, 이를 보고 있는 피험자의 특정 뇌파(P300 뇌파)가 발생하는 것을 이용한 BCI 기술을 사용하였습니다.
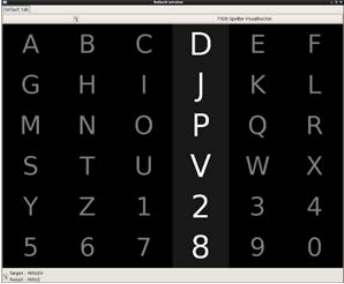
이러한 뇌파는 사람마다, 같은 사람이라도 시간에 따라 다르기 때문에 기존에 연구된 대부분의 BCI 시스템들은 학습 단계를 필수적으로 가지게 됩니다. 이 논문에서는 여러 피험자들의 뇌파 데이터를 이용하여 일반화된(별도의 학습 단계가 필요하지 않은) BCI 분류기를 개발하고자 하였습니다.
모델은 10개의 노드를 가진 1개의 은닉층만 가지고 있는 Feedforward Neural Network 모델이 사용되었고, 테스트할 때 피험자 본인의 데이터를 제외한 나머지 피험자들만의 데이터를 이용하여 테스트한 경우(ZTNN)와 피험자 본인의 데이터까지 포함한 경우(WSNN)의 두 가지로 테스트를 진행했습니다.
결과적으로, 기존의 SWLDA 방법을 사용한 경우(86.1%)와 WSNN 테스트 방법을 사용한 경우(84.22%)에는 큰 차이가 없었으나, ZTNN 방법을 사용한 경우(74.54%)는 유의미한 성능 하락이 있었습니다. 실제 이 분류기를 사용할 때, 피험자 데이터를 추가하여 테스트 하는 방법(WSNN)은 기존의 방법과 차이가 없으므로, ZTNN 방법을 사용했을 때의 정확도가 논문에서 설계한 방법의 ‘진짜 정확도’입니다.
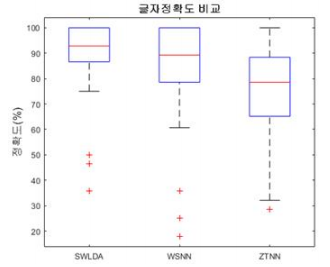
비록 성능이 많이 떨어지긴 했으나, 커뮤니케이션을 위한 최소의 정확도(70%)는 확보했으므로, 유의미한 결과를 얻었다고 합니다. 이를 이용해, 기존 방법을 이용했을 때 상대적으로 낮은 정확도가 나오는 일부 피험자들에게 타인의 데이터를 이용하여 정확도를 높일 수 있다고 합니다.
이 실험에 사용된 데이터가 55명의 피험자로부터 얻어진 데이터인데, 과연 이 데이터가 모델을 학습하는 데에 충분한가? 하는 생각이 듭니다. 데이터의 양 자체도 부족하겠지만, 55명이라는 표본이 과연 얼마나 모집단을 잘 대표할 수 있으며, 곧 일반화된 모델을 학습시킬 수 있는지에 대한 생각도 들었습니다.
시퀀스 투 시퀀스(Sequence-to-sequence) 모델을 활용한 대화생성 결과 비교 분석
NLP 분야에서 문장 생성 기법 역시 많은 관심을 받고 있는 주제 중 하나입니다. 저도 text 데이터를 이용한 Generative Model에 대한 관심이 있었고, 챗봇 개발 과제 때문에 이 논문에 관심이 생겨 듣게 되었습니다.
이 논문에서는 Multi-layer의 Bidirection RNN 모델을 사용한 인코더와, Attention Mechanism과 LSTM 모델을 사용한 디코더로 구성되어 있습니다.
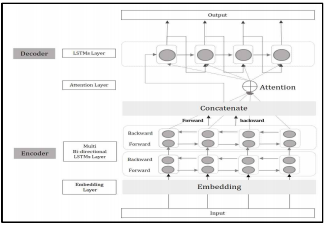
LSTM 디코더는 Greedy Search와 Beam Search의 두 가지 디코더를 이용한 모델을 선정했습니다. 데이터는 국립국어원의 대화 말뭉치와 영화, 드라마 대본을 합쳐 구성하였습니다.
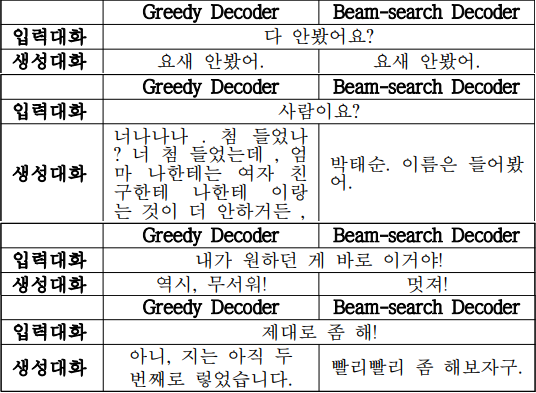
Greedy Search의 경우 특정 어휘가 반복되거나, 말이 되지 않는 어휘를 생성하는 등의 문제가 있었고, Beam Search는 의도에 맞는 답변을 생성하였습니다. ROUGE, BLEU 등의 스코어는 Greedy Search의 경우가 더 높았으나, 실제 생성된 대화를 보면 Beam Search의 경우가 더 적절한 답변을 보였습니다.
평소에 Generative 모델이 진정한 의미의 인공지능이 아닐까 생각했습니다. 지금 진행 중인 챗봇 과제도 현재는 Rule 기반의 알고리즘을 이용하여 텍스트를 주고받고 있는데, 가능하다면 Generative하게 문장을 생성하여 사용자에게 정보를 전달할 수 있도록 하고 싶습니다.